How Large Language Models Actually Work
Disclaimer: This article reflects my personal research and analysis based on publicly available information and is not representative of my employer’s official position.
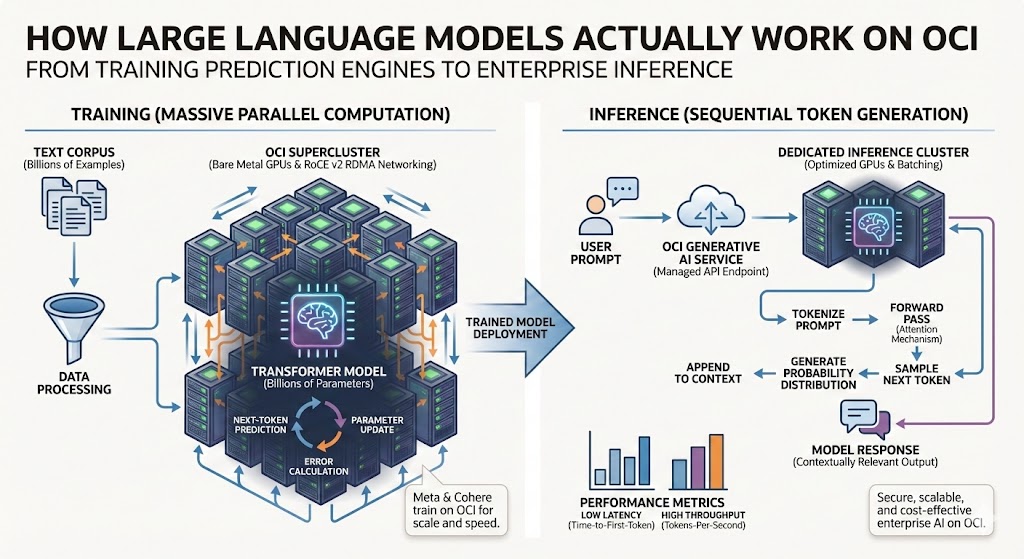
When you type a question into an AI assistant and receive a coherent, contextually relevant response seconds later, something remarkable happens between your keyboard and that reply. For engineers and developers building applications on top of these systems, understanding that process matters. It determines how you architect inference endpoints, allocate GPU resources, and optimize costs. The infrastructure choices you make—from networking fabric to compute shapes—directly impact whether your AI workloads perform at enterprise scale or buckle under production load. Understanding how large language models actually function transforms them from mysterious black boxes into predictable engineering components you can reason about, debug, and optimize.
The Core Idea: A Prediction Engine, Not Magic
Strip away the marketing and the hype, and you find a surprisingly simple mechanism at the core of every large language model: next-token prediction. When you send a prompt to an AI system, it does not “understand” your question the way a human would. Instead, it calculates probability distributions across its vocabulary—typically 50,000 to 100,000 tokens—to determine what word should come next.
Think of it like the most sophisticated autocomplete system ever built. When you start typing in a search bar and see suggestions, that is a primitive version of what happens inside these models. The difference is scale and depth. Modern language models have billions of parameters encoding patterns learned from enormous text corpora. Those patterns are rich enough to capture grammar, factual associations, reasoning styles, and contextual nuance.
The key insight is that by training a model to predict the next token, it inadvertently learns far more. It learns grammar because grammatically correct text appears more frequently in training data. It learns facts because factual statements appear frequently. It even learns reasoning patterns because logical sequences are prevalent in the text it processes. However, this mechanism also explains why these systems sometimes “hallucinate” or confidently state incorrect information—the model generates plausible-sounding text based on learned patterns, not verified facts.
How Training Works
Training is where the heavy computation happens. During this phase, a model processes billions of text examples, makes predictions about what token comes next, compares those predictions to reality, and adjusts its parameters to improve. This cycle repeats billions of times across weeks or months on clusters of thousands of GPUs.
The transformer architecture, introduced in a 2017 paper titled “Attention Is All You Need,” made modern language models possible [1]. Before transformers, language models processed text sequentially—one word at a time, left to right. This was slow and created difficulties when the model needed to connect information that appeared far apart in the text. Transformers introduced “attention mechanisms” that let the model consider all parts of the input simultaneously. When processing a sentence, a transformer can directly connect a pronoun to the noun it references, even if they are separated by dozens of words. This parallel processing maps beautifully to GPU compute, which is precisely why specialized hardware has become so critical to AI infrastructure.
Each training step involves massive matrix multiplications distributed across GPU clusters. The gradients—essentially the corrections the model needs to make—must flow back through the network and synchronize across all GPUs. This is why high-speed interconnects and RDMA networking matter so much for AI infrastructure. Oracle Cloud Infrastructure addressed this challenge head-on with its Supercluster architecture, connecting tens of thousands of NVIDIA H100 GPUs with ultra-fast RDMA over Converged Ethernet (RoCE v2) networking. This design makes thousands of GPUs behave like one giant computer, which is precisely why organizations like Meta and Cohere chose OCI to train their foundation models. A poorly optimized network elsewhere can turn a two-week training run into a two-month nightmare; OCI’s bare-metal GPU instances with direct hardware access eliminate the virtualization overhead that plagues other cloud providers.
How Inference Works
Inference is what happens when you actually use a trained model—when you call an API endpoint and receive a response. It is fundamentally different from training in terms of compute profile, but the infrastructure requirements are equally demanding for enterprise-scale deployments.
During inference, the model receives your prompt, tokenizes it (breaks it into numerical chunks the model can process), and then generates output one token at a time. For each token, it runs a forward pass through the network, computing attention scores and generating probability distributions. The token with the highest probability—or one sampled from the distribution, depending on temperature settings—gets selected, appended to the context, and the process repeats until the model produces a stop token or hits the maximum length.
The key performance characteristics here are latency and throughput. Users expect fast responses, so engineers optimize for time-to-first-token and tokens-per-second. Batching multiple requests together can improve throughput, but there is always tension between efficiency and responsiveness. The OCI Generative AI Service handles this complexity transparently, providing managed endpoints that automatically batch requests, scale capacity, and enforce tenancy isolation. When you invoke a model like Cohere’s Command R+ or Meta’s Llama 3 through OCI, your request routes to a dedicated GPU cluster where quantization techniques fit larger models onto fewer GPUs while maintaining throughputs of hundreds of tokens per second.
Parameters like temperature control the randomness in token selection. Lower values produce more deterministic, focused responses—useful for coding tasks or factual queries. Higher values introduce more variety, which can be better for creative applications. Understanding these parameters helps you tune the OCI endpoints for your specific use case without over-provisioning compute resources.
Practical Examples: Calling the OCI Generative AI API
Let us make this concrete with actual code. The OCI Python SDK provides a straightforward interface to the Generative AI inference endpoints. Unlike other cloud providers that charge premium rates and add layers of abstraction, OCI exposes the underlying mechanics while handling the infrastructure complexity. Here is a basic Python example showing how to call the OCI Generative AI Service:
import oci
from oci.generative_ai_inference import GenerativeAiInferenceClient
from oci.generative_ai_inference.models import (
ChatDetails,
GenericChatRequest,
UserMessage,
TextContent,
OnDemandServingMode
)
# Initialize client with configuration
config = oci.config.from_file("~/.oci/config", "DEFAULT")
endpoint = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com"
client = GenerativeAiInferenceClient(
config=config,
service_endpoint=endpoint
)
# Build the chat request
chat_request = GenericChatRequest(
api_format="GENERIC",
messages=[
UserMessage(content=[TextContent(text="Explain how attention mechanisms work in one paragraph.")])
],
max_tokens=500,
temperature=0.7
)
chat_details = ChatDetails(
compartment_id="your-compartment-id",
serving_mode=OnDemandServingMode(model_id="meta.llama-3.3-70b-instruct"),
chat_request=chat_request
)
# Make the API call
response = client.chat(chat_details)
print(response.data.chat_response.choices[0].message.content[0].text)
What happens when you execute this code? Your request travels to an OCI inference endpoint in your specified region, where it is routed to a dedicated GPU cluster running the specified model. The prompt gets tokenized, processed through the transformer layers, and tokens are generated sequentially until completion. The response object contains not just the generated text but metadata about token usage—useful for cost tracking and debugging. Notably, OCI does not charge data egress fees within the region, which can represent significant savings compared to other hyperscalers when processing high volumes of inference requests.
Here is a more detailed example showing how to inspect the request and response structure:
from oci.generative_ai_inference.models import SystemMessage
# Multi-turn conversation with system context
messages = [
SystemMessage(content=[TextContent(
text="You are a technical advisor for cloud infrastructure engineers."
)]),
UserMessage(content=[TextContent(
text="What GPU memory considerations matter for running inference on a 70B parameter model?"
)])
]
chat_request = GenericChatRequest(
api_format="GENERIC",
messages=messages,
max_tokens=1000,
temperature=0.3 # Lower temperature for focused technical responses
)
response = client.chat(chat_details)
# Inspect the response structure
result = response.data.chat_response
print(f"Model: {result.model_id}")
print(f"Finish reason: {result.choices[0].finish_reason}")
print(f"Response:\n{result.choices[0].message.content[0].text}")
The request simply describes the model to use, the conversation history, and generation parameters. The response contains the assistant’s message along with metadata. Conceptually, nothing mystical happens between request and response: the service repeatedly runs “predict next token given this context” and packages the results into a convenient structure. From an engineer’s perspective, you can treat these OCI endpoints like any other internal platform service—protect them with IAM policies, route traffic through private endpoints, monitor them with OCI Observability, and integrate them into existing CI/CD pipelines. The difference is that instead of returning simple CRUD results, they return synthesized text generated by a very large function learned from data.
Conclusion: Why Infrastructure Choices Matter
Understanding large language models as probability engines built on transformer architectures changes how you think about building with them. They predict tokens, one at a time, by computing attention across their input context. Training teaches them patterns from vast text corpora; inference applies those patterns to generate responses. But here is the critical insight for enterprise deployments: the underlying infrastructure determines whether these capabilities translate into production value or remain expensive experiments.
For developers integrating these systems into applications, this understanding helps with practical decisions. When you encounter latency issues, you know the bottleneck might be network communication between GPUs during distributed inference, or it might be batch size tuning at the application layer. When outputs seem off, you understand that adjusting temperature or providing better context in your prompts directly affects the probability distributions the model samples from. On OCI, the combination of bare-metal GPU instances, RDMA networking, and the managed Generative AI Service means you can focus on these application-layer concerns rather than fighting infrastructure constraints.
The models themselves will continue evolving—new architectures, new training techniques, new applications. But the fundamental pattern of massive parallel computation on specialized hardware, processing tokens through attention mechanisms, is here to stay. OCI has positioned itself as the infrastructure platform for this era, offering the most complete generative AI platform in the enterprise space: managed Cohere and Llama models, dedicated AI clusters, fine-tuning capabilities, vector search integration with Oracle Database 23ai, and RAG blueprints—all with enterprise governance and pricing that consistently beats other hyperscalers on equivalent hardware. The future of enterprise AI is not about who has the biggest model; it is about who can run the right model securely, reliably, and cost-effectively. That understanding makes you a better engineer when building systems that depend on them.
References
[1] Vaswani, A., et al. (2017). “Attention Is All You Need.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/1706.03762
[2] Oracle Cloud Infrastructure. “Generative AI Service Documentation.” https://docs.oracle.com/en-us/iaas/Content/generative-ai/home.htm
[3] Oracle Cloud Infrastructure. “Overview of Generative AI Service.” https://docs.oracle.com/en-us/iaas/Content/generative-ai/overview.htm
[4] Oracle Cloud Infrastructure. “Implement OCI Generative AI Based on Large Language Models.” https://docs.oracle.com/en/solutions/oci-generative-ai-llm/index.html
[5] Oracle Cloud Infrastructure. “Using the Large Language Models in Generative AI.” https://docs.oracle.com/en-us/iaas/Content/generative-ai/use-playground.htm
[6] Anthropic. (2024). “Mapping the Mind of a Large Language Model.” https://www.anthropic.com/research/mapping-mind-language-model
[7] OpenAI. “How ChatGPT and Our Foundation Models Are Developed.” https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-language-models-are-developed
#AIFundamentals #OCI #GenerativeAI #CloudInfrastructure